Introduction
These are my reflections on the talks. I’m trying to be open-minded and take a balanced view of the positive and negative opinions that were exchanged. If that’s not your thing then this probably isn’t for you.
The Venue
The Warner theatre was amazing. It reminded me of the State Theatre back home in Sydney.

Inside the place had a pleasantly baroque feel, and everyone seemed to be relaxed and comfortable:

Day 1
 Unlocking data-driven systems
Unlocking data-driven systems
[Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep] [Github]
Paul deGrandis opened with a story about his experiences on a Cognitect client. He kicked off this truism that was echoed throughout the conference:
Data > Functions > Macros
Now the reason why this was important was this snippet of detail:
“These 26 lines [of #Clojure] replaced 2000 lines of JS and 1000 lines of HTML”
Now there wasn’t a lot of detail on that or how it worked. Indeed, some criticised this saying it was an advertisement for Cognitect about proprietary technology.
To some the tone of this critique seemed a little Statler and Waldorf.

The vibe I took from this was the Paul Graham programming ‘bottom-up’ theme. Paul says in a Lisp language you write a DSL for your problem domain and then solve the business problem in the DSL. I took it this was what Paul deGrandis was driving at. If so – this is quite cool.
Now the great thing about Paul D is that he is now the Pedestal guy. If you’ve worked with Pedestal – you’ll know it embodies this philosophy (particularly in the deprecated versions of the front-end).
 Cursive: a different type of IDE Om nom nom nom
Cursive: a different type of IDE Om nom nom nom
[Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep] [Pre-Conj Interview] [Github]
Anna Pawlicka has come from London and working with Bruce Durling at MastodonC. She was demonstrating some of the visualisations you can do with Om. She used d3.js and dimple.js to produce charts quickly.
Anna did enunciate the benefits of Om extremely clearly, stating that Om relieves us from querying the DOM – we can just use clojure data structures and diff using reference equality check – and present from there.
Anna demonstrated using http-kit and sente with core.asyc to update components, and these were coordinated with go blocks on the server and client.
Anna described reference cursors in Om, using them for enabling and disabling transitions, and seeing information in a part of the application state.
Anna also followed up the conference by creating an Om-Cookbook – something we’ve been needing for a while.
 Cursive: a different type of IDE
Cursive: a different type of IDE
[Video] [Twitter Cursive] [Twitter Colin] [Pre-Conj Prep] [Pre-conj Interview] [Github]
Colin Fleming is a charming New Zealander who has picked up the old La Clojure plugin for IntelliJ and is busy turning it into a commercial-grade product.
Colin touched on a lot of developer-expectations that go with Clojure entering the mainstream. Most mainstream developers do expect context-sensitive, ast-aware tooling. The broader theme was an ‘IDEs vs Editors’.
What was fun about this talk was the ribbing he gave Emacs. (Which Bozhidar very humorously returned later in the day.) The theme of this was mainly around it being a ‘text-only’ tool.
He also made a comment on people’s critique of Intellij, saying they could type faster in emacs. His response to that was ‘lack of typing is a feature not a bug’.

He touched on the infrastructure of Intellij – providing a large index in which you can feed in the program elements and AST. This menas you can discriminate based on fully-qualified symbol – for searches and suggestions. You want to be able to do a ‘find usages’ and do a ‘smart find and rename’ [not text based].
He did some refactorings to demonstrate the tool that got the crowd excited. I saw the people around me kicking back in their chairs and banging their fists with excitement.
 Generating Generators [Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep] [Pre-conj Interview] [Github]
Generating Generators [Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep] [Pre-conj Interview] [Github]
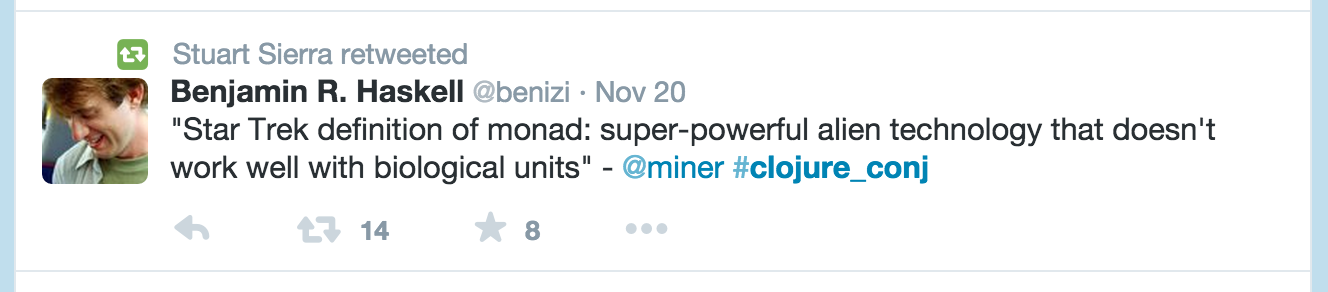
Steve Miner gave a great introduction to using test.check in Clojure and how you set up generators to work on it. His big idea was that the libraries around this could be better – and so he has built the Herbert library. This makes generating parameters (eg that match regex filters) easier
One of the great things about this talk was the warm-up on generators for Ashton’s talk on Saturday. Steve mentioned there were plenty of opportunities for performance improvement. One trap to stay away from was trying to co-join to regexes, as this was unlikely to succeed in the current implement. Steve was entertaining, the star-trek theme was fun, and he is just a great guy to talk to.
 JVM Creature Comforts
JVM Creature Comforts
[Video] [Twitter] [Pre-Conj Prep] [Github]
Ghadi Shayban got an intro from Stuart Sierra, “Ghadi is also a classical pianist… which is what I guess you need these days to use emacs…”. (bah-bom tish). [Laughter and boos from the crowd.] Stuart’s acerbic sense of humour cracks me up. (I think this got edited out of the youtube clip.)
Ghadhi spent a fair bit of time on language internals – including relating development with invokedynamic on Clojure to what had already been done on the Nashorn JavaScript engine for the JVM.

Ghadi also talked about the Graal and Truffle projects. (Graal is a general performance project to improve the performance of the JVM relative to Native Code – basically the hotspot infrastructure has been moved from C++ to Java. Truffle is a language framework on top of Graal that handles the AST). To prove the power of Truffle someone had implemented C in Truffle (TruffleC).
Ghadi finished up by saying that he could see some potential improvements with local vars (and the invokedynamic framework). He was hoping for optimisation with control flow, object manipulation, value manipulation, invocation, stack traversal.
 The evolution of the Emacs tooling for Clojure [Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep] [Pre-conj interview] [Github]
The evolution of the Emacs tooling for Clojure [Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep] [Pre-conj interview] [Github]
Bozhidar Batsov is an effervescent guy all the way from Bulgaria. I got to meet him the day before at the Scheme workshop – it seemed we had both flown roughly the same number of hours to be there (about 20 hours in transit).
He continued his charm on stage, with a very confident, polished and witty delivery. (The photo of him here is terrible). He introduced himself as “a night in the order of emacs”. He then proceeded to gentle return the “editor ribbing” given to him by Colin earlier in the day. (I saw them having breakfast together in the hotel, exchanging ideas the morning after – it was all good fun).
Bozhidar started with a discussion of the history of emacs and Clojure, and all the plugins people had written over the years. He also talked a little about the State of Clojure Survey, saying that Cider had gone from 48% to 42% usage, but was still dominant.
One the most interesting points Bozhidar stated, “In 30 years, no one will have heard of Cursive, but they will still be using Emacs.”
 Developing Music Systems on the JVM with Pink and Score[Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep][Pre-Conj Interview] [Github]
Developing Music Systems on the JVM with Pink and Score[Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep][Pre-Conj Interview] [Github]
Steven Yi is a musician and Phd student. His talk revolved around music theory and its computational implementation. You may be familiar with other Lisp-like music systems like Sam Aaron’s work on Overtone, or Andrew Sorenson’s work on Extempore. As you may be aware, Overtone runs on a system called SuperCollider (which does music generation from the algorithmic instruction from Overtone). I believe (although I could be wrong) that Extempore uses SuperCollider as well.
Steven’s talk was more fundamental than these, rather than focus on algorithmic coordination of music, his focus was on the generation of the music (ie replacing SuperCollider). Steven was implementing a library called Blue which runs on CSound to do this.
Steven made the point that digital audio is a sequence of numbers, where time and space are linked. Steven is a great guy to talk to.
 Inside Transducers
Inside Transducers
[Video] [Twitter] [Pre-Conj Prep] [Github]
Rich Hickey was the reason that most people I spoke to came to the conference. He is an extraordinary speaker who speaks with a casual authority, and who for a lot of people changed the way they think about computing problems.
Rich Hickey started off with a heartfelt thanks to his wife who was in the audience, who had been there for him all the time he had invested in Clojure. I found it special because it touched on the tension that is often felt with hobby projects and family.

Rich has made popular the study of Etymology amongst Clojurians – and this was no exception. He took the time to review the latin origins of the word-components of transducers.
This talk went deeper into stateful transducers. It also felt like Rich alluded to some blog posts by Peter Frankel and Christophe Grande.
Rich mentioned future projects in the transducer pipeline (under consideration): parallel transducers, supportive implementation macros, primitives, multi-arity, kv transduce, functional stateful transducers. He also talked about future work into core.async.

This one is a definite must-watch (but you’ve already figured that out).
Day 2

 Helping voters with Pedestal, Datomic, Om and core.async [Video] [Pre-Conj Prep] [Github NH] [Github CS]
Helping voters with Pedestal, Datomic, Om and core.async [Video] [Pre-Conj Prep] [Github NH] [Github CS]
Nathan Herzing & Chris Shea opened day 2 with a killer demonstration of live-coding in Clojure with Datomic and Om.
Their talk was about building tools to update voters about their mail-in ballots at Turbovote. There was some stuff in here about integrating with legacy systems that matched my own experiences.
This is worth it alone for the inspiration it will give you to get better at your tooling (and perhaps live-coding) skills.
 Persistent Data Structures for Special Occasions
Persistent Data Structures for Special Occasions
[Video] [Pre-Conj Prep] [Github]
Michał Marczyk was introduced as having been specially selected by Rich Hickey. He dropped into the detail of data structure implementation and talked about the benefits of FlexVec, an improvement on Clojure’s vectors. He then explained in detail why in many cases they perform better.
This was one of the most dense talks in the whole Conj. Good for a brain-stretch.
 Applying the paradigms of core.async in ClojureScript
Applying the paradigms of core.async in ClojureScript
[Video] [Slides] [Twitter] [Blog] [Pre-Conj Prep] [Pre-Conj Interview] [Github]
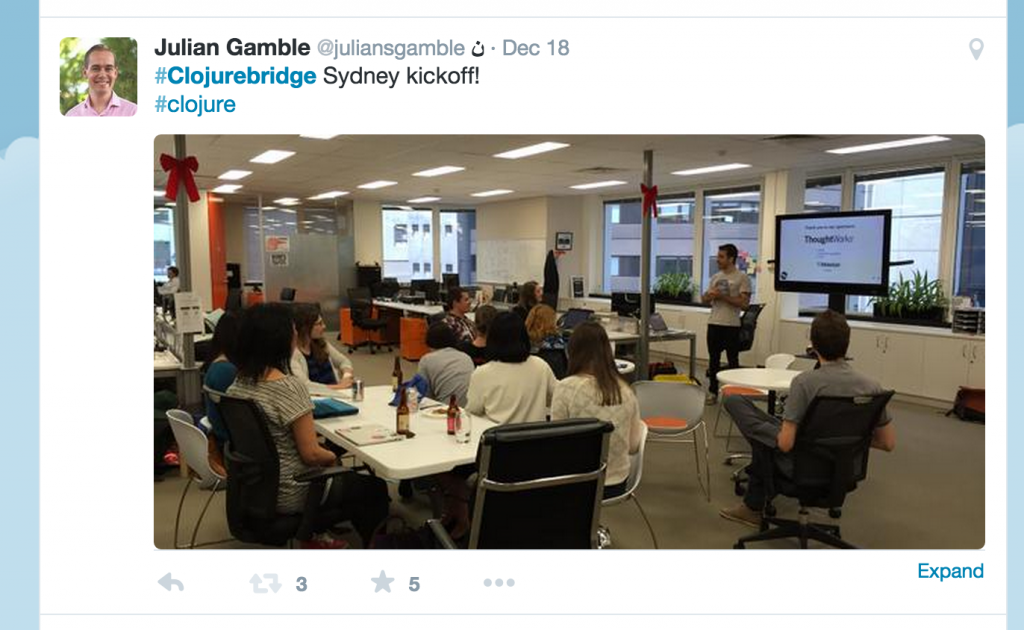
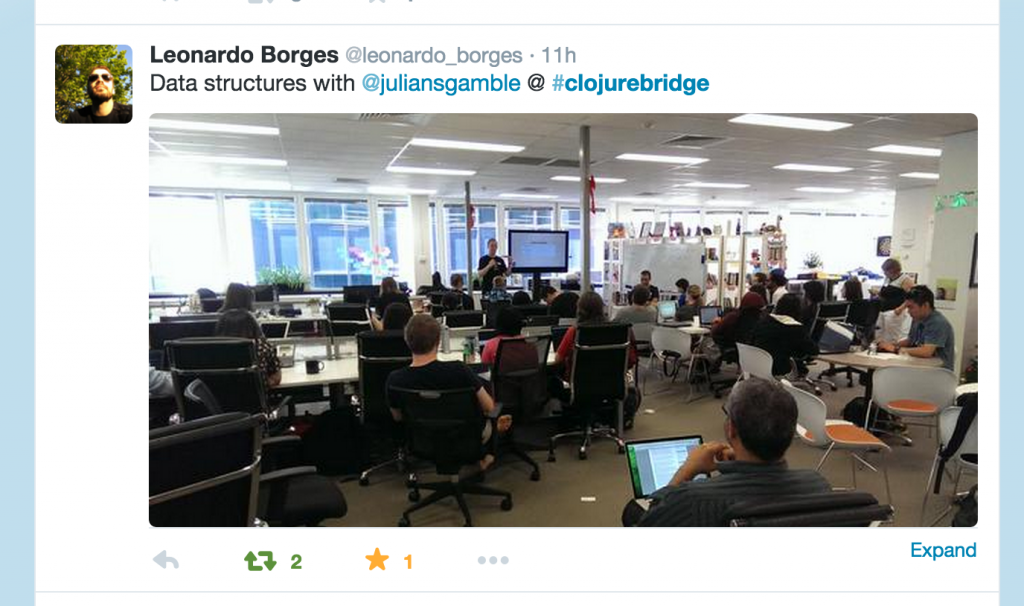
Julian Gamble is the guy writing this post! I talked about core.async syntax and green threads in Clojure and ClojureScript with some visual demos. I’m just going to include some things other people said.
Eric Normand also had some interesting commentary. (Eric is a friend – and so this is well-taken). I found this feedback really freeing – and will allow myself to level-up.

I was thrilled to be a part of Clojure Conj. I learned so much from this experience, and had a blast.
 Variants are Not Unions
Variants are Not Unions
[Video] [Twitter] [Blog] [Pre-Conj Prep] [Pre-conj Interview] [Github]
Jeanine Adkisson is this super-intelligent compiler-writer who is fun and opinionated. From the start this talk was delivered with animations in vim – and it stayed information-dense from there.
There was a dinner with a bunch of people after and I had the chance to Jeanine about LR2 parsers and monadic parsers. She is great to talk to.

 Exploring four hidden superpowers of Datomic
Exploring four hidden superpowers of Datomic
[Video] [Slides] [Twitter EW] [Twitter LC] [Blog LC] [Pre-Conj Prep] [Github EW][Github LC]
Lucas Cavalcanti & Edward Wible presented on the 4 (really 9) superpowers of datomic. You could see that Datomic has massive benefits in the financial services space.
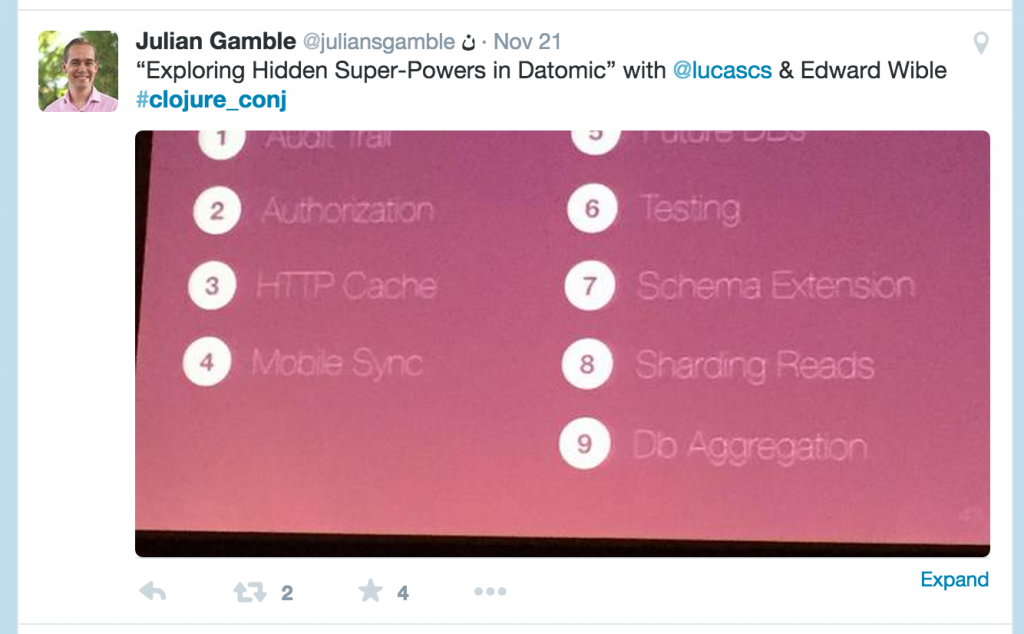
What was most interesting to me about this talk was Edward’s background (Princeton Computer Science, then MBA, Private Equity, then Boston Consulting). He had moved to San Paulo to be the CTO of a bank that was starting from scratch. He was writing the code by hand with the team. He was there to promote this company and invite people to join him. What incredible vision and execution! (If I didn’t have family I was tempted to take six months to join him) This guy is one to watch.
 Making Games at Runtime with Clojure
Making Games at Runtime with Clojure
[Video] [Site] [Pre-Conj Prep] [Github]
Zach Oakes delivered one of the must-see presentations at Conj 2014.

This was the first time I had been to a conference talk that had everyone around me was laughing so hard they were crying.

Zach talked about his love for writing games, playing games, teaching programming through writing games. He took special joy in seeing how people used his library.
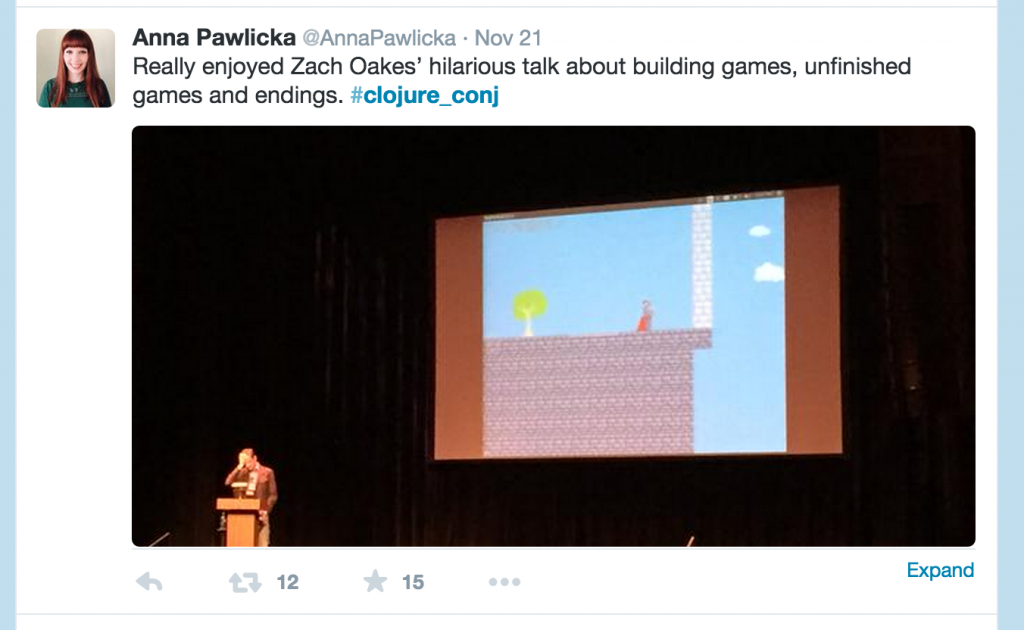
I hope I haven’t built up your expectations too much – but this was extremely memorable.
 Cló: The Algorithms of TeX in Clojure
Cló: The Algorithms of TeX in Clojure
[Video] [Twitter] [Blog] [Pre-Conj Prep] [Github]
Glenn Vanderburg is an experienced presenter and it shows. Now who in the Clojure community has ever tried to scratch an itch with a hobby project? Glenn set out to rewrite the Tex editor produced by Donald Knuth in Pascal, into Clojure.

This was the premise for a journey into the tools from 30 years ago, the constraints of the systems of that time and a deep appreciation for how good things are now:
The conclusion of this project is interesting, both in its reflection of the miracles Knuth worked at that time, and the power and constraints of the Clojure ecosystem. Glenn is such good fun to watch.
Day 3
 Always Be Composing
Always Be Composing
[Video] [Twitter] [Blog] [Pre-Conj Prep] [Github]
Zach Tellman started his talk talking about sierpinski triangles and waxed lyrical from there. (Zach used to maintain a 3d library in Clojure called Penumbra).
Zach touched on the truism from the start of the conference “prefer data over functions over macros”. Zach said it was great the spectrum of options we have, but it wasn’t a perfect model. He said it was similar to when the periodic table came out, that it had some gaps, which indicated perhaps there were some other things to look for.
Zach touched on transducers as a specific sort of composition. His concern was for people new to Clojure, that they would require a lot of foundational explanation.
Zach then talked about regular expressions as a composition mechanism, and how it had lead him to write the automat libary. He talked about the richness of automata theory as a set of tools. He said it was quite hard to accomplish anything.
Zach then talked about queuing with core.async and how backpressure was an emergent property. He said the causality of the problem leads to code complexity, and the only tool we had at the moment to work with this was a macro. (The Go macro). He definitely wasn’t saying it was bad. (Zach is the author of lamina which came out before core.async and has some similarities for queuing without the green threads macro).
Zach’s talk was driving at the catch-phrase “prefer composition over X” and talked about all the approaches and pitfalls that this entails. He said that the problem with “just composing something” is that it is inextricably tied up in what you’re trying to accomplish. He was trying to capture all the different forces at play.
This is quite philosophical, but really worth watching.
 Building a Data Pipeline with Clojure and Kafka
Building a Data Pipeline with Clojure and Kafka
[Video] [Twitter] [Blog] [Pre-Conj Prep] [Github]
David Pick delivered a real-world experience using Clojure, Kakfa and redshift. David wanted to keep the data warehouse in sync with his primary database, but PostgreSQL didn’t prove helpful in the approaches he tried. He needed a highly resilient system.
The benefit of Kakfa was atomic operations, persistence and the ability to replay the steam to an external sink.
The original web client had been written in Ruby, but they found that the clients for Kafka were JVM based, the and concurrency operations for when Kafka blocks were useful.
They also needed a specialised way to shut the infrastructure down and step through each part. Actors turned out to be a good fit for this, and kept the same semantics that goroutines held for them. Actors also helped avoid race conditions. These semantics were provided by pulsar/quasar.
The other thing he liked about Kakfa was that the data scientists could integrate into it directly for real-time fraud monitoring. They also use it for web-hooks to send async events, and report generation (some massive reports) which can happen in real-time.
 Generative Integration Tests
Generative Integration Tests
[Video] [Twitter] [Blog] [Pre-Conj Prep] [Github]
Ashton Kemerling explained his ‘real-world’ experiences using generative testing. Building on Steve’s explanation of Generative testing to describe the shape of the data and run multiple cases, he talked about how he would let the machine hammer the possibilities and find the edge-cases. He was using Selenium to hammer a website, which even he was a a bit surprised about.
The main downside was that duration is complicated, you can’t tell how long it was going to take to run. The benefit was that in finding a failure scenario that others described with 10 steps, he could narrow it down to 2 steps. He also said it was good for missed errors.
His technique involved getting a snapshot of database state into memory, and then load it each time the browser is loaded, with a browser cache flush.
This was quite an inspiring talk, and convinced me that test.check is ready for real-world usage.
 Stewardship: the Sobering Parts
Stewardship: the Sobering Parts
[Video] [Twitter] [Blog] [Pre-Conj Prep]
Brian Goetz delivers one of the must-watch talks for the conference. You can see that Brian has attended a conference or two in his lifetime and he is a very experienced speaker. Some have said this was a celebration for Brian:
His premise was that he was a language designer, and seeing COBOL jump the shark with the addition of the alter command, he was kept up at night worrying about that happening to Java.
Brian took the time to touch on Clojure cliches like etymology and ponies, and clearly had a fun time doing it.
Brian talked about project Valhalla, which is a set of performance improvements in Java 10 for specialised generics, value types and var handles. Brian also talked about Project Panama, (which may come into Java 9) which is bringing ffi, data layout control and autolayout.
This is a must-watch.
Must-Watch Videos
These are the ones that stuck out in my mind:
(I’d really appreciate it if you watched mine – but totally understand if you don’t have time).
Personal Reflections
Almost none of the big names from the Clojure Community bar Rich were on the stage. This seemed strange at first, until I realised it was about community-building. In speaking to people, they were coming from their local Clojure meetups and seeing the most-polished, most-entertaining, most-insightful presentations from across the country and the world. Most of those presentations (and speakers) had been polished with the involvement of their local group. This was a celebration of all the little Clojure communities coming together.
This year Clojure moved in the ‘adopt’ sphere of the Thoughtworks Radar. Some have commented jokingly on what this really means. I do remember reading that the original Conj was an intimate group of less than 100 people. Now with 500 people, and half of them new to the Clojure Conj, in a sense it felt like the Clojure community has come of age. In some ways I feel a sense of loss, that this edgy small community is changing into something different. On the other hand it’s quite exciting to think what will happen if we can pull ourselves together and solve big problems in software development.
(Did I mention I’m also writing a book called Clojure Recipes?) 🙂