Day 1 – Thu, Dec 11th 2025
Kent Beck – Sustainable Augmented Development

Kent told us we have been thrust from a predictable world of extraction into a brave new era of exploration, where AI amplifies our leverage but requires us to prioritize high-level systems thinking and design optionality over raw coding speed.
Rather than fearing obsolescence, we must embrace our duty to mentor junior developers, whose fresh adaptability combined with our experienced guidance is the only way to prevent this powerful “genie” from creating unmanageable technical debt.
Ultimately, that we must resist the anxiety to simply run faster and instead claim your time to experiment and learn, remembering that your life is a finite opportunity for craftsmanship, not just a race to clear tickets.
Alexander Chatzizacharias – A Fun and Absurd Introduction to Vector Databases

We have entered the era of “vector magic,” where high-dimensional mathematics allows computers to finally understand context, turning everything from wizard spells to Pikachu images into number arrays that measure semantic meaning.
While the tooling landscape is now so crowded that you can essentially “pick the logo you like,” the real power lies in using these dense vectors to connect distinct worlds, like building a “Shazam for heavy metal” that deciphers growled lyrics.
Ultimately, the talk leaves us with a hilarious survival strategy for the future: since AI is mastering human language, our only hope to stay off the grid might be communicating exclusively in unintelligible grunts.
Jim Webber – The Pub-Time Parliament
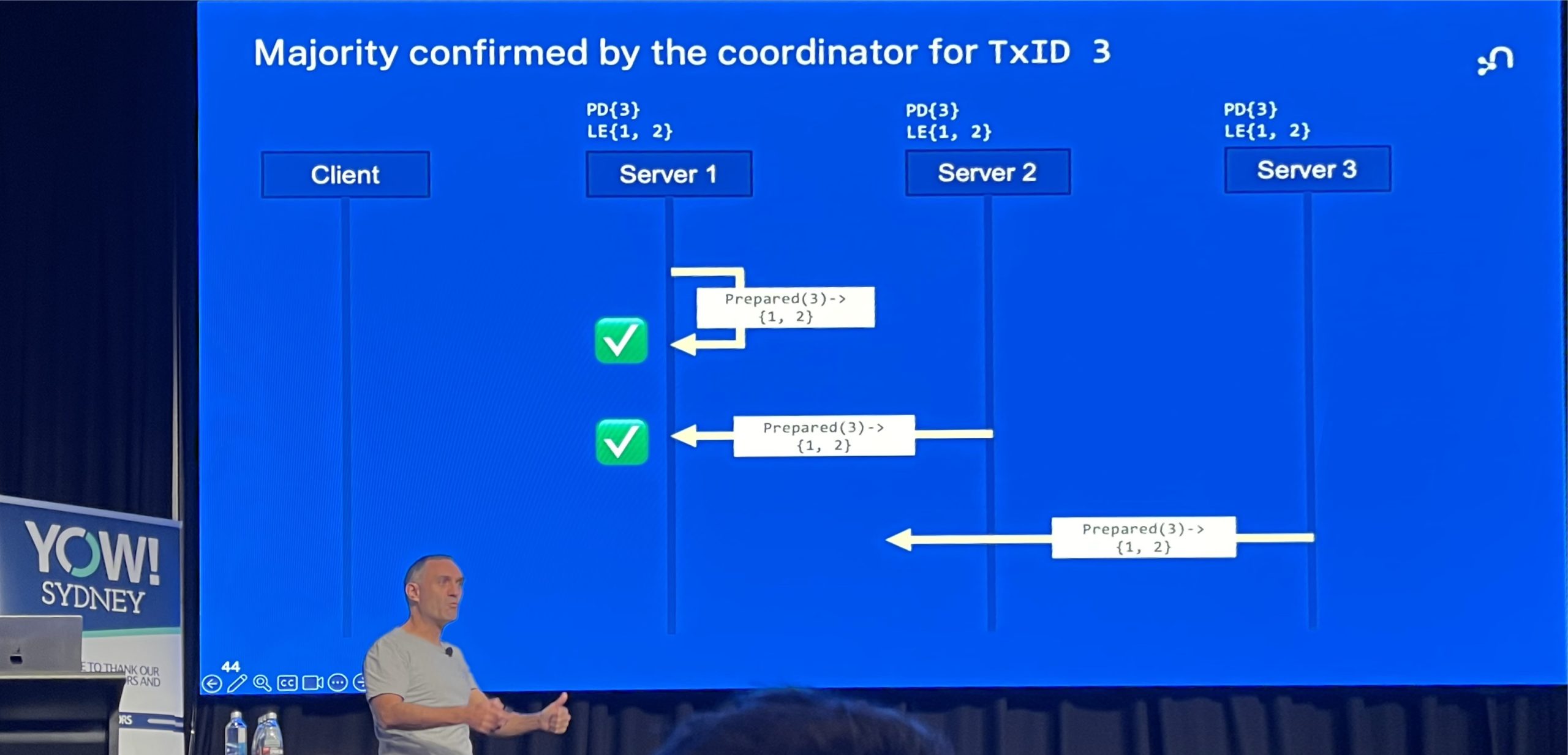
Jim Webber traces the evolution of distributed consensus from the academic complexity of Paxos to the empathy-driven design of RAFT, arguing that true engineering brilliance favors understandable solutions over intellectual “flexing.”
He introduces RIOT, a protocol designed to handle the unique tensions of sharded graph databases, proving that we can achieve massive scale and strict correctness without creating systems too complex for humans to manage when disaster strikes.
Ultimately, this talk serves as a reminder that the most robust architectures are built on kindness and clarity, urging us to “be awesome to each other” by designing systems that our future selves can actually understand.
Roy van Rijn – Pushing Java to the Limits: Processing a Billion Rows in Under 2 Seconds
This talk showcases a thrilling “Advent of Code” style competition, pushing Java performance from a baseline of 4 minutes and 50 seconds down to an astonishing 1.5 seconds by ruthlessly optimising every layer of the computing stack.
The journey from simple streams to victory involved deep mechanical sympathy, leveraging advanced techniques like SIMD As A Register (SWAR) for fast delimiter finding, and using magic numbers to write branchless code that fundamentally eliminated CPU pipeline bottlenecks .
The takeaway is that true high-performance engineering means exploiting the underlying hardware, from using Unsafe and memory-mapped files to eliminating object allocation and understanding L3 cache shared access, proving that peak performance is a continuous, fascinating process of questioning every assumption.
Nicolas Fränkel – WebAssembly on Kubernetes

WebAssembly has evolved from a client-side browser optimization into a powerful, secure, and fast universal binary format for polyglot applications across the entire stack, delivering on the promise of “write once, run anywhere” with exceptionally small binary sizes.
The exciting journey to run WASM on Kubernetes is demonstrated through lean, multi-flavor containers, showcasing a massive reduction in image size down to a mere 2MB by replacing the OS layer with a simple WASM runtime shim.
However, be warned: while this world is blazing fast and full of potential, the ecosystem is currently moving so rapidly that dependency instability can break production code in a week, meaning this is the perfect arena for innovation, but not yet for stability-hungry enterprises.
Conor Hoekstra – Enter the Matrix
This talk presents “Vibe Coding” as the evolution of software craftsmanship, urging you to take the “red pill” and embrace AI tools like Cursor to dramatically maximize your coding output by making you a more precise, high-level architect rather than a typist.
The true secret to unlocking this potential is not just using the tools, but actively experimenting with the latest models and feeding them detailed prompts, enabling them to handle the vast majority of the implementation details for you.
Ultimately, your expectations must be reset: modern AI assistance paired with array programming paradigms (like BQN) and highly optimized GPU frameworks (like Parrot) completely transforms what is possible, allowing you to focus on elegant, dense solutions at speeds previously unimaginable.
Sam Aaron – Beyond Sonic Pi: Tau5 and the Art of Coding with AI
Sam Aaron’s journey with Sonic Pi reveals that programming’s true power lies not in business logic, but as a vibrant tool for human expression, using music as the infectious bridge to teach complex concepts like concurrency to children.
Driven by the need to make this experience accessible and live-codable in the browser, he faced the monumental challenge of porting a complex C++ synthesizer (SuperCollider) to WebAssembly, a task only made possible by treating the LLM as a tool that constantly tries to gaslight you, demanding meticulous verification and code annihilation.
Ultimately, by overcoming technical impossibilities and refusing to let institutional barriers stamp out interest, Aaron is creating a new world of “fun human expression and joy,” inviting us to redefine programming as an exciting, performative art form that everyone is eager to embrace.
Day 2 – Fri, Dec 12th 2025
Michael Feathers – Conceptualisation – The Form Behind Names

The core struggle behind “God classes” is a conceptual drift where the structure outgrows its original name, challenging the rigid Aristotelian view of categorization and demanding we recognize that our software abstractions are always lossy maps, not the full territory.
To refactor effectively, we must move beyond simple renaming by fundamentally evolving the conceptual space, leveraging insights from Prototype Theory and the potential of LLMs to discover new, deeply resonant ways of classifying the complex behaviors we model.
Therefore, our task is to become conscious vocabulary inventors, coining precise new terms and comparing models across different contexts to break the inertia of existing names, thus fostering a shared understanding that empowers us to manage the inevitable growth and complexity of our systems.
Simon Brown – The C4 Model – Beyond The Basics

The C4 model provides a practical, notation-independent framework for visually documenting software architecture at increasing levels of detail: System Context, Containers (process boundaries like web apps or databases), Components, and Code.
To maximize usefulness, focus on the first two levels, Context and Containers, which define system boundaries and inter-process network interactions, treating containers not as deployment artifacts but as crucial isolation boundaries to clarify technology choices and communication paths.
Ultimately, C4 is a tool for achieving architectural clarity; by using its structure to map complex systems, you move your team past the “ad hoc” documentation stage toward a mature, shared understanding that enables large-scale organisation and efficient system evolution.
Kevin Dubois – Create (Agentic) AI-infused Apps, the Easy Way
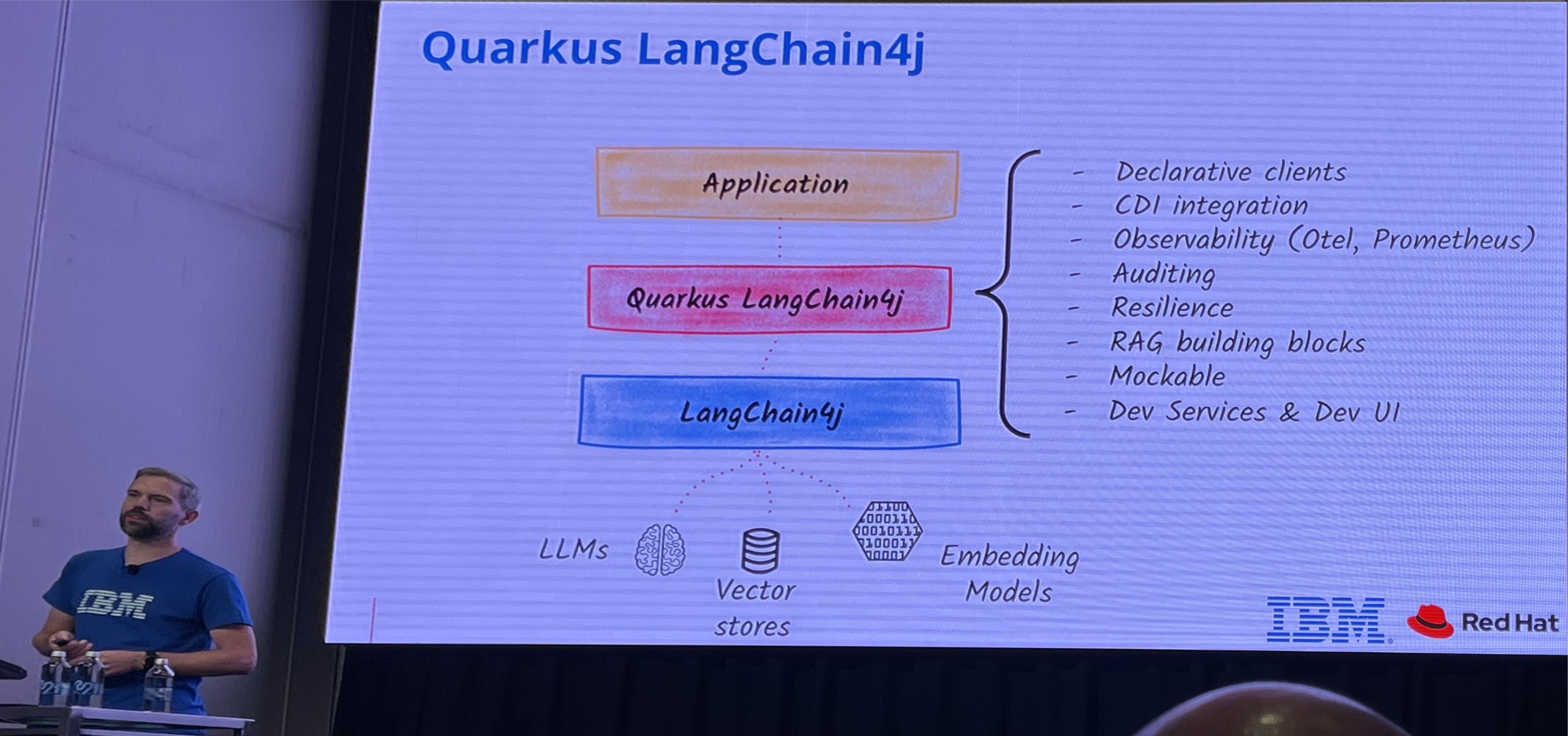
Kevin Dubois showed how to build powerful agentic AI apps effortlessly using the Quarkus stack and Langchain4j, leveraging features like structured POJO returns, conversational memory, and Retrieval-Augmented Generation (RAG) to inject specific knowledge.
He demonstrated control with the Model Context Protocol (MCP), enabling deterministic tool use, while critical GuardRails and fault tolerance mechanisms ensure your agents, even when orchestrating multiple specialised experts, are safe and enterprise-ready.
Kevin showed the future of development where minimal code creates sophisticated, goal-based autonomous systems with hot-reloading developer experience, proving that integrating cutting-edge AI into Java applications is now both simple and profoundly powerful!
Nada Amin – Metaprogramming, Synthesis, and Verification

This talk was a vision of the future, led by Nada Amin, illuminated the goal of Verified Synthesis, uniting the expressive power of neural language models with the certainty of formal verification systems like Dafny, defining a frontier where code is generated with provable correctness.
The presentation showcased the dedication required to achieve high-assurance software, detailing how techniques like design-by-contract verification and structural induction, even when aided by AI scaffolding, provide strong signals that ensure complex systems, such as the AWS authorisation engine, are formally guaranteed to uphold their semantics at scale.
This pushes the boundaries of programming itself by exploring powerful paradigms like relational programming and utilising constraint solvers (Holey, minikanren) not just for debugging, but for synthesising correct-by-construction code, promising a future of trustworthy intelligent systems that fundamentally change how we reason about and build software.
- Dafny Sketcher (https://github.com/namin/dafny-sketcher),
- multi-stage miniKanren (https://github.com/namin/staged-miniKanren),
- VerMCTS (https://github.com/namin/llm-verified-with-monte-carlo-tree-search),
- Holey (https://github.com/namin/holey).
Rod Johnson – Why Do We Need An Agent Framework?

The AI revolution’s next phase demands a shift from fragile, non-deterministic Python notebook experiments to robust, enterprise-grade applications, especially in mission-critical business processes where failures are costly.
Rod Johnson’s Embabel framework addresses this challenge by maximizing determinism through careful orchestration, breaking complex goals into small, testable steps, and deeply integrating with existing business systems and type-safe domain models, leveraging the strengths of Java developers.
Everything we learned about building resilient software—types, transactions, and testing—is now more vital than ever to build reliable agents that move beyond personal augmentation into trustworthy, goal-driven automation.
Sarah Meiklejohn – 13 Years of Cryptocurrency De-anonymization (and Counting)
Despite the initial premise of anonymity, the globally visible nature of public ledgers like Bitcoin makes them fundamentally traceable, allowing researchers and law enforcement to effectively de-anonymise transactions by treating cryptocurrency like traceable digital cash.
By applying clustering heuristics, like identifying change addresses, it is possible to group disparate addresses back to a single entity, allowing investigators to track vast sums of money across the blockchain, even tracing funds stolen from exchanges or used in Dark Net Markets.
This work transforms the blockchain into a powerful tool for accountability, offering a testament to human ingenuity: though technology attempts to obscure, the careful study of transaction patterns can always bring transparency to complex systems.